
10月13日消息,近日,苹果公司的AI研究团队发表了一篇题为“Understanding the Limitations of Large Language Models in Mathematical Reasoning”的论文,揭示了大型语言模型(LLM)在数学推理方面的显著局限性。

尽管这些模型在生成人类水平的文本方面表现出色,但当处理简单的数学问题时,即使问题仅进行了微小的改动,如添加无关信息,模型的表现也会急剧下降。
在论文中,研究人员通过一个简单的数学问题证明了这一点。
他们提出了一个关于采摘猕猴桃的问题:奥利弗在周五挑选了 44 个猕猴桃,然后他在周六挑选 58 个猕猴桃,周日,他采摘的猕猴桃数量是周五的两倍。奥利弗有多少个猕猴桃?
此时,LLM能够正确地计算出答案。
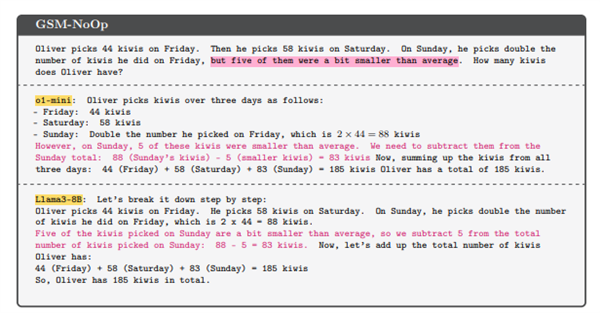
但是,一旦问题中加入了无关的细节,如“其中5个奇异果比平均小”,模型便给出了错误的答案。
研究人员进一步对数百个类似的问题进行了修改,发现几乎所有问题的修改都导致了LLM回答成功率的大幅降低。

这一发现表明,LLM并未真正理解数学问题,而是更多地依赖于训练数据中的模式进行预测。
当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。
虽然LLM在许多领域表现优异,但其推理能力仍有待改进。
【本文结束】如需转载请务必注明出处:
责任编辑:文祥
文章内容举报



















